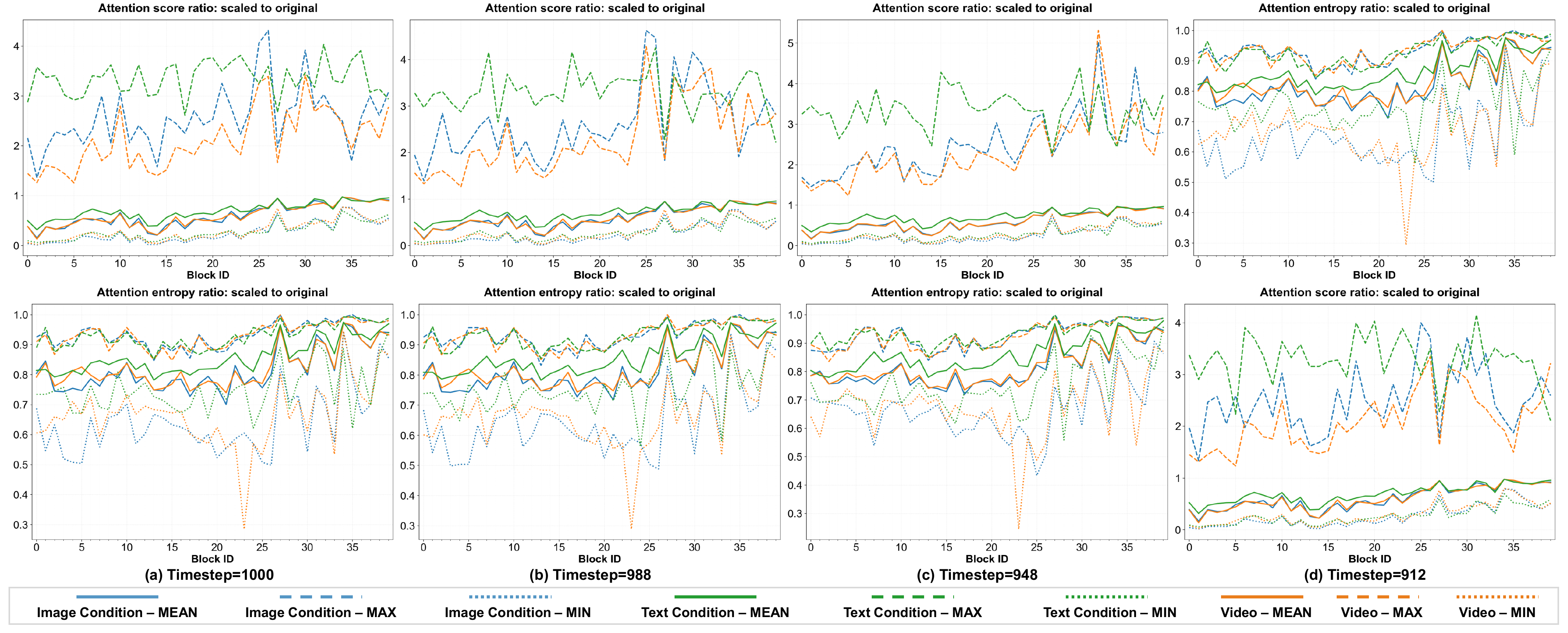
Text-guided image-to-video generation has made substantial progress, yet it still struggles to execute text-specified edits that require substantial changes to a reference image (e.g., object addition, removal, or modification). Empirically, our analysis reveals that this stems from
visual dominance, where the reference image causes severe attention dispersion, inhibiting the model's ability to incorporate new semantic information.
To address this, we propose AlignVid, a training-free intervention that re-calibrates the model's internal attention distribution. Drawing on an energy-based perspective of attention, AlignVid employs Attention Scaling Modulation (ASM) to reduce attention entropy and concentrate focus on semantic tokens, alongside Guidance Scheduling (GS) to maintain generation stability.
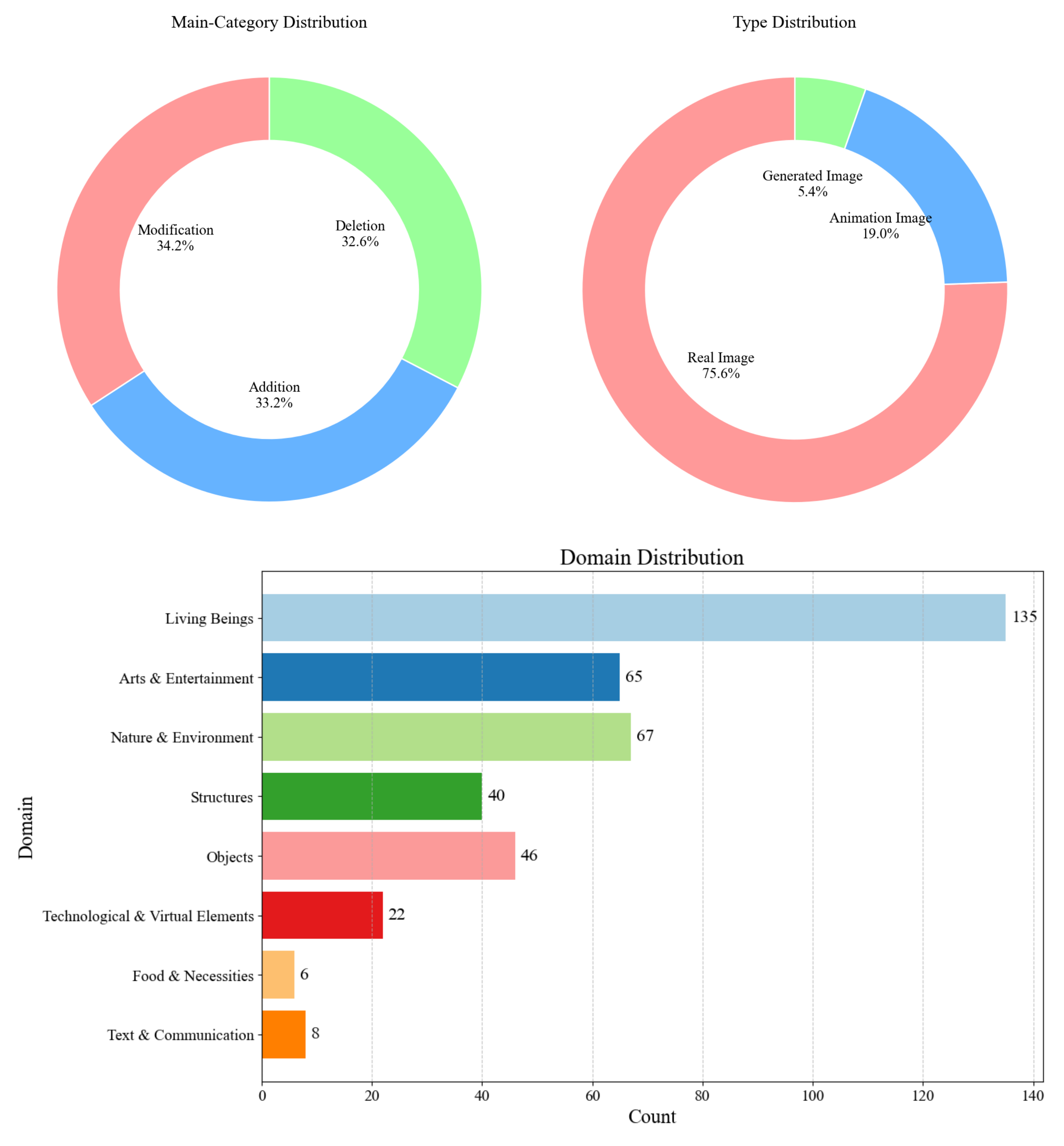
To rigorously assess this capability, we present OmitI2V, a comprehensive benchmark for evaluating prompt adherence across object modification, addition, and deletion. Extensive experiments demonstrate that AlignVid effectively enhances semantic fidelity with negligible computational overhead.